Už vím jak - vytvořit interpret co umí FOR

Po přečtení druhého dílu našeho seriálu možná zjistíte, že ty teoretické rekurzivní stromy a zásobníkové automaty k něčemu praktickému opravdu jsou. I OOP návrhové vzory zde kupodivu najdou své využití.
Postup tvorby slíbeného jednoduchého interpretru cyklu "for" BASICU ze světa osmibitů v C#.
Opět si můžete kód jednoduše vyzkoušet v prohlížeči. Tento kód pěkně odkrývá úplné "základy" programování, tj. převod zadaného textu programovacího jazyka do "řeči" počítače, který ji pak provádí. Zmíněný postup se mi už velmi hodil při tvorbě vlastního jednoduchého "domain specific" jazyka pro vyhodnocení složitých dotazníků, kdy bylo třeba zapsat jednoduše "uživatelsky" prostým textem bodové hodnocení různých dotazníkových dat v mém programu.
Kód dále ukazuje, že rekurzivní "stromové" struktury nejsou žádné nepraktické teoretizování a v jedné své části velmi elegantně využívá i datovou strukturu Stack (zásobník).
Navíc kód používá i složitější základní "Gang of Four" návrhový vzor "Interpreter" a od stejného gangu poměrně jednoduchý návrhový vzor "Prototype". Vše je tak vidět na jednom intelektuálně zajímavém kódu rozumné délky. A to je pravá výzva, programování například podle "Czechitas" přece může zvládnout úplně každý, takže by pochopení principů a přiloženého kódu nemělo být nijak zvlášť intelektuálně náročné. Nějak si ovšem pořád neumím představit, že "Czechitas" tuto zajímavou problematiku na svých kurzech pro začátečníky nové adeptky programování učí. Navíc nepopírají kurzy Czechitas už tím, že jsou určeny pouze pro jednu genderově jasně vymezenou polovinu populace, svoji logiku všeobjímající a spravedlivé rovnosti genderů? Nebyl by lepší výraz "adept*y*ky programování" či jak se to feministicky spravedlivě píše? Provokativní otázky nechám bez odpovědi, můžeme přece všechny ty chudáky co se moří se začátky programováním nazývat jakkoli, ale až tyto pokročilejší postupy a struktury umožňují rozumnou algoritmizaci složitějších programátorských úloh. Bez nich nejde pořádně zpracovat ani organizační "vícevrstvá" struktura ve firmě s jejími vztahy nadřízený-podřízený, to znamená postup od ředitele (kořen stromu) až k poslednímu vrátnému.
Pokud někomu nestačí náš velmi "primitivní" parser, na závěr ještě vyzkoušíme, jak náš kód BASICu rozparsovat i reálným parserem Basicu z .NET knihovny Roslyn.
Interpret cyklu for v C#
Se slzou v oku jsem zavzpomínal na programování v Atari Basicu, které jsem jako nadšený technicky založený pionýr obstojně ovládal díky počítačovému kroužku v "Domě pionýrů a mládeže".
Pokusíme se nyní přiblížit v C# interpretaci části tohoto jazyka, který se v původní originální verzi "vlezl" do pouhých 8 kB ROM (smekám před tvůrci, toto nedokázal v té době ani Microsoft, jeho interpret byl větší). V originálním Atari BASICu, pokud uživatel při editaci stiskne klávesu "RETURN", se aktuální řádek zkopíruje do vstupního řádkového bufferu BASICu v paměti mezi 580 a 5FF16. Tokenizér Atari BASICu prohledává text a převádí každé klíčové slovo na jednobajtový token (například PRINT je 2016), každé číslo na šestibajtovou hodnotu s pohyblivou desetinnou čárkou, každé jméno proměnné na index do tabulky a tak dále. Program je tak uložen jako jednoduchý "parsovací strom" (Parser tree). Hlouběji jsem reprezentaci Atari Basicu nestudoval, ale řekl bych, že je asi uložený "tokenizovaně" pouze každý samostatný řádek a o nějaké rekurzivní reprezentaci programu se mluvit nedá (navíc v rekurzivní reprezentaci celého programu by se špatně skákalo v kódu kamkoli pomocí GOTO).
https://en.wikipedia.org/wiki/Atari_BASIC
V našem případě budeme postupovat podobně, ovšem "parsovací strom" vytvoříme z celého programu a pomocí OOP návrhového vzoru "Interpreter" budeme tento "parsovací strom" spouštět, tj. interpretovat. Vzor "Intrepreter" se učí (pokud se vůbec učí a neřekne se, že je to zbytečný a složitý vzor) na primitivních příkladech typu římských číslic (viz příklad v odkazu), my vyzkoušíme složitější interpret, co umí vyhodnocovat jednoduché matematické výrazy, tisknout a spouštět cyklus. Jako kontrolní příklad vezmeme dva BASICové cykly v sobě:
10 FOR X=0 TO 9
20 FOR Y=0 TO 9
30 LET SUMY = SUMY + Y
40 NEXT Y
50 LET SUMX = SUMX + X
60 NEXT X
70 PRINT SUMX
80 PRINT SUMY
Budeme tak muset vytvořit podporu proměnných, cyklu for a operace přiřazení a sčítání v oboru přirozených čísel. V paměti vznikne moc pěkný rekurzivní "Parser tree", navíc se budeme muset starat o jednoduchý "Context", ve kterém je nejdřív uložený postupný stav parsování a pak hodnoty proměnných.
Objektová analýza
Návrhový vzor "Interpreter" definuje, jakým způsobem implementovat interpretaci nějakého "jazyka" (který nemusí být přímo programovací, viz příklad s římskými číslicemi) pomocí objektově orientovaného programování. Vzor řeší reprezentaci kódu "jazyka" v paměti jako množinu objektů a jejich následné spuštění. Naopak vůbec neřeší problém parsování zdrojového kódu do tohoto objektového modelu.
Původní vzor "Interpreter" tak rozšíříme i o budování "parsovacího stromu". Abstraktní IExpression rozšíříme o metodu "Construct" která vybuduje objekt IExpression aktuálního řádku (nejdřív tak "interpretujeme" řádky zdrojového kódu k vybudování objektového stromu, pak tento strom opět pomocí stejného interpretru spustíme). Pokud je na aktuálním řádku cyklus "for" tak se do něj uloží všechny řádky až po NEXT, tím vznikne žádaná "stromová" struktura. Celé naše snažení shrnuje UML diagram na obr. 1, který má jak popsaný "Class diagram", tak i rozparsovaný "Instance diagram" našeho programu.
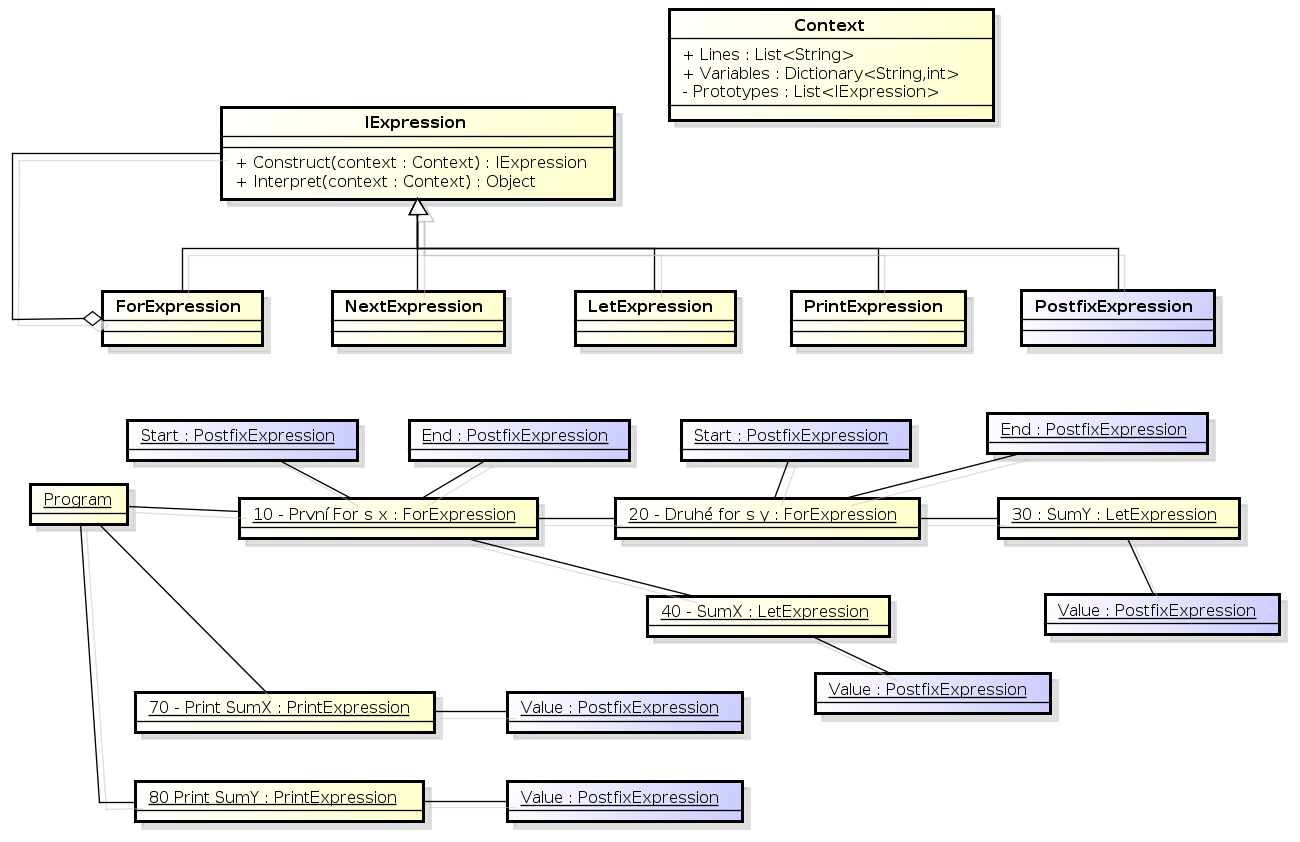
Obr. 1 - Class a instance diagram
Tokenizace
Jednotlivé příkazy poznáváme pomocí regulárních výrazů, veškeré výrazy v nich převedeme na postfix notaci objektu PostfixExpression. Parsování je tak poměrně primitivní - na řádku nalezneme jednu ze tří možností příkazu (For, Let a Print) a pomocí metody "Construct" prototypových instancí (ekvivalent metody Clone() vzoru "Prototype") vytvoříme vyplněnou instanci dané Expression.
Zajímavá je třída PostfixExpression. Využívá přepis klasické "infixové" notace, například 2*(9-2*3) na "postfixový" zápis 2 9 2 3 * - *, který se velmi jednoduše vyhodnocuje.
Vyhodnocení "parsovacího stromu"
Vyhodnocení do objektového stromu přepsaného programu je celkem jednoduché. Na hlavní úrovni (na obr. 1 pod "Program") máme pouze tři řádky, které postupně spustíme pomocí metody "Interpret". Objekt "Context" pak drží hodnoty všech proměnných (jsou tak globální jako v Atari Basicu). Základní objekty (ForExpression, LetExpression, PrintExpression) při svém běhu vyhodnocují "své" PostfixExpression vypočítané pomocí aktuálních hodnot proměnných z Context. Vyhodnocení "postfixových" výrazů pomocí zásobníku (v příkladu použiji výraz 2*(9-2*3) přepsaný na "postfixový" zápis 2 9 2 3 * - * z minulé kapitoly) probíhá jednoduše:
- Na zásobník se skládají čísla (čísla se do výrazu při vyhodnocení doplní podle aktuálních hodnot proměnných) do první operace, tj. 2 9 2 3
- Provede se daná operace "*" s dvěma posledními čísly (2 a 3), a výsledek se místo nich zapíše na vrchol zásobníku. Zásobník teď vypadá takto: 2 9 6
- S posledními dvěma čísly se opět provede zadaná operace "-" a zapíše se: 2 3
- Zbývá poslední * a na zásobníku máme výsledek 6!
Máme opravdu velmi elegantním způsobem vyřešený výpočet výrazu s prioritou operátorů a závorkami. Parsování a přepis výrazu je tímto velmi jednoduchý, doslova na "pár" řádcích.
Využití už uloženého „parsovacího stromu“
Pomocí "contexu" a proměnných můžeme náš vybudovaný "strom" používat jako standardní přeloženou aplikaci. Stačí kód mírně přizpůsobit:
10 FOR X=STARTFOR TO 9
20 FOR Y=STARTFOR TO 9
30 LET SUMY = SUMY + Y
40 NEXT Y
50 LET SUMX = SUMX + X
60 NEXT X
70 PRINT SUMX
80 PRINT SUMY
a interpretovat ho jednou bez nastavených proměnných a podruhé s nastavením proměnných (v příkladu na konci nastaveno takto). SUMX a SUMY na nulu nastavovat nemusíme, ale přičítalo by se pak do nich dál.
basicInterpreter.Variables["STARTFOR"] = 1;
basicInterpreter.Variables["SUMX"] = 0;
basicInterpreter.Variables["SUMY"] = 0;
Reálný parser
Reálné parsování je samozřejmě sofistikovanější a podrobnější. Předpokládá připojenou knihovnu Roslyn, proto nejde zkoušet v našem online prostředí.
using Microsoft.CodeAnalysis;
using System.Linq;
using Microsoft.CodeAnalysis.VisualBasic;
public static void ParseVb()
{
string programText = @"
Public Sub Main(args() As string)
Dim sumX AS Integer = 0
Dim sumY As Integer = 0
for x As Integer = 1 to 9
for y As Integer = 1 to 9
sumY = sumY + y
next y
sumX = sumX + x
next x
Console.WriteLine(sumX)
Console.WriteLine(sumY)
End Sub";
SyntaxTree tree = VisualBasicSyntaxTree.ParseText(programText);
SyntaxNode root = tree.GetRoot();
int count = root.ChildNodes().Count();
string sumXline = root.ChildNodes().ElementAt(0)
.ChildNodes().ElementAt(3)
.ChildNodes().ElementAt(2).ToString();
}
https://learn.microsoft.com/en-us/dotnet/csharp/roslyn-sdk/get-started/syntax-analysis
Výsledek parsování je velmi podobný našemu, první blok "for" obsahuje v sobě druhý. Program v .NET se neinterpretuje, ale uloží do interpretovaného byte kódu. Výsledná aplikace tak není ani kompilovaná, ani iterpretovaná, prostě něco mezi tím co se snaží sebrat všechny výhody obou přístupů.
root.ChildNodes().ElementAt(0) - blok funkce Main
.ChildNodes().ElementAt(3) - blok dvou cyklů for
.ChildNodes().ElementAt(2).ToString() - řádek sumX = sumX + x
Příště se podíváme, co jsou iterátory v části "Už vím jak na iterátory".
Zdrojový kód
Zdrojový kód (zde ke stažení) stačí celý vložit do online kompilátoru a spustit.
Zdrojový ukázový kód
|
|
Přidáno: 10.11.2023 17:57:57
|